Homework 2#
Due: May 15th 11:59PM (Submit via Canvas)
In addition to answering the written questions below, please complete the following Jupyter notebook exercises found here
05_rocket_trajopt.ipynb06_stochastic_dynamic_programming.ipynb07_mpc.ipynb
Trajectory optimization#
1. Rocket landing trajectory optimization#
You should complete notebook 05_rocket_trajopt.ipynb first before answering this question.
(a)#
The trajectory optimization problem from part (iv) of the notebook may sometimes be infeasible, particularly if your initial guess is far from the feasible set. For instance, setting the initial control input to zero can easily lead to infeasibility.
To address this, introduce slack variables into the optimization problem to relax one or more of the constraints, thereby ensuring that the solver can always find a feasible solution. Specify which constraints you are choosing to relax (for example, state or control constraints), describe how you incorporate the slack variables, and explain how you penalize their use in the objective function to discourage excessive constraint violation. Provide your reasoning for choosing which constraints to relax.
Is this the only way to ensure feasibility? Briefly outline an alternative strategy, such as using a different form of regularization, constraint softening, or modifying the initial guess mechanism.
(Optional) Feel free to implement your proposed formulation verify that it indeed performs what you expect it to do.
(b)#
How does the choice of the trust region penalty weighting affect the convergence rate towards a (locally) optimal solution. Run some experiments and provide some plots to demonstrate the relationship between trust region penalty weights and convergence rate.
2. Expressing trajectory optimization with linear dynamics as quadratic programs.#
(a)#
Consider the following trajectory optimization problem
In this problem, you will express the above trajectory optimization problem as a quadratic program of the form
Let \(z = \begin{bmatrix} x_0^T & x_1^T & \dots & x_N^T & u_0^T & u_1^T & \dots & u_{N-1}^T \end{bmatrix}^T\).
(i)#
Rewrite the dynamics constraints \(x_{k+1} = A_k x_k + B_k u_k\) for \(k = 0, \ldots, N-1\) in the quadratic program form \(A_\text{dyn} z = b_\text{dyn}\). Clearly define the structure and dimensions of \(A_\text{dyn}\) and \(b_\text{dyn}\) in terms of \(z\). Explicitly specify how variables are arranged and how each time step’s dynamics are represented within this equality constraint.
(ii)#
Express the initial condition constraint \(x_0 = x_\mathrm{init}\) in the linear equality form \(A_\text{init}z = b_\text{init}\). Clearly specify the structure and dimensions of \(A_\text{init}\) and \(b_\text{init}\) based on how the decision variable \(z\) is defined. Describe precisely which elements of \(z\) these matrices select and how they enforce the initial state constraint.
(iii)#
Using your answers from parts (i) and (ii), clearly write how the full equality constraint \(Az = b\) can be constructed by combining the dynamic constraints and initial condition constraints. Explicitly specify how \(A_\text{dyn}\), \(b_\text{dyn}\), \(A_\text{init}\), and \(b_\text{init}\) are stacked or concatenated to form the complete \(A\) and \(b\) matrices in the quadratic program format.
(iv)#
Rewrite the state inequality constraints \(G_k x_k + h_k \leq 0\) for all \(k = 0, \ldots, N\) in the standard quadratic program form \(G_\text{ineq} z \leq h_\text{ineq}\). Clearly specify the structure, dimensions, and arrangement of \(G_\text{ineq}\) and \(h_\text{ineq}\) in terms of the decision variable \(z\). Explicitly describe how each time step’s constraint is embedded in \(G_\text{ineq}\) and \(h_\text{ineq}\), making clear which parts of \(z\) are involved for each \(k\).
(v)#
Rewrite the control input (actuator) constraints \(u_{\min} \leq u_k \leq u_{\max}\) for \(k = 0, \ldots, N-1\) in the standard quadratic program form \(G_\text{u} z \leq h_\text{u}\). Clearly specify the structure, dimensions, and arrangement of \(G_\text{u}\) and \(h_\text{u}\) in terms of the decision variable \(z\). Explicitly describe how each time step’s control constraint is embedded in \(G_\text{u}\) and \(h_\text{u}\), making clear which parts of \(z\) are involved for each \(k\).
(vi)#
Using your answers from parts (iv) and (v), write how the complete inequality constraint \(Gz \leq h\) is formed by combining the state and control input constraints. Explicitly specify how \(G_\text{ineq}\), \(h_\text{ineq}\), \(G_\text{u}\), and \(h_\text{u}\) are stacked or concatenated to produce the full \(G\) and \(h\) matrices in the quadratic program format. Clearly indicate their structure and dimensions in terms of the decision variable \(z\).
(vi)#
Express the cost function
in the standard quadratic program form
Clearly describe the structure, dimensions, and block-diagonal form of the matrix \(P\) in terms of \(Q\), \(R\), and \(Q_N\), and specify how \(p\) and \(r\) should be chosen to match the given objective. Explain which blocks of \(P\) correspond to which states \(x_k\) and control inputs \(u_k\) for all \(k\).
(b)#
Now, consider the following modified trajectory optimization problem, inspired by the SQP approach from notebook 5a. This problem includes additional trust region penalty terms in both the state and control input objectives, and also in the goal state.
Here,
\(x_k\) denotes the state at time step \(k\),
\(u_k\) is the control input at time step \(k\),
\(A_k\), \(B_k\), and \(C_k\) describe the linearized dynamics at each time step,
\(Q\), \(R\), \(Q_\mathrm{trp}\), \(R_\mathrm{trp}\), and \(Q_N\) are the state, input, trust region penalty, and terminal cost weights, respectively,
\(\tilde{x}_k\) and \(\tilde{u}_k\) are reference state and input trajectories,
\(x_\mathrm{init}\) and \(x_\text{goal}\) are the prescribed initial and desired final states,
\(G_k\), \(h_k\) encode stagewise state constraints,
\(u_{\min}\), \(u_{\max}\) are input bounds.
Based on your formulations from part (a), explicitly write out all the matrices and vectors—such as \(P\), \(p\), \(r\), \(A\), \(b\), \(G\), and \(h\)—that define the standard Quadratic Program (QP) form of this trajectory optimization problem. Clearly express each in terms of the problem data and parameters presented above, and specify how these matrices/vectors are constructed from the trajectory optimization problem setup.
3. Differential flatness#
(Adapted from AA 274 from Stanford University)
(Note: Technically, this is not a trajectory optimization problem, as there is no objective function to minimize over possible trajectories. Rather, it is a trajectory generation problem, where the goal is to construct a feasible trajectory that satisfies the system constraints.)
In this problem, you will explore methods for generating smooth trajectories for non-holonomic wheeled robots, and in the process, gain familiarity with important geometric properties of these systems.
A non-holonomic system is one for which the allowable instantaneous motions are subject to constraints, even though the system can ultimately reach any position and orientation through a sequence of admissible moves. A classic example is a car: while it can eventually maneuver to any pose in the plane, it cannot move directly sideways at any instant, since its velocity is constrained to the direction its wheels are oriented.
Your objective is to synthesize a smooth, feasible trajectory for such a system by leveraging the concept of differential flatness, which enables explicit trajectory construction and control design in the presence of these motion constraints.
Differential flatness
Differential flatness is a structural property of certain nonlinear systems that allows the state and control inputs to be expressed entirely in terms of a specific set of variables, called flat outputs, and their time derivatives.
For a system to be differentially flat, there must exist a mapping such that:
where \(x\) is the state, \(u\) is the control input, and \(y\) is the flat output. This property is powerful for trajectory planning because it effectively “inverts” the dynamics. Instead of solving a complex boundary value problem by integrating the equations of motion forward, a designer can simply define a smooth path for the flat outputs. Since the system is flat, the necessary control inputs and intermediate orientations required to follow that path can be calculated algebraically, ensuring that the resulting trajectory is physically feasible by construction.
Consider the dynamically extended unicycle model.
The system dynamics are given by:
Here,
The state vector is \(\mathbf{x} = \begin{bmatrix} x & y & \theta & v \end{bmatrix}^T\), where
\((x, y)\) is the Cartesian position of the robot’s center,
\(\theta\) is its heading angle measured from the \(x\)-axis, and
\(v\) is the forward velocity of the robot along its main axis.
The control input vector is \(\mathbf{u} = \begin{bmatrix} a & \omega \end{bmatrix}^T\), where
\(a\) is the linear acceleration (rate of change of \(v\)), and
\(\omega\) is the angular velocity (rate of change of \(\theta\)).
This model captures the essential constraints of non-holonomic wheeled robots and serves as a foundation for planning and controlling their trajectories.
(a)#
Derive explicit expressions for \(\ddot{x}\) and \(\ddot{y}\) in terms of the system variables \((v, \theta, a, \omega)\). Starting from the given dynamics of the extended unicycle model, show how the second derivatives of \(x\) and \(y\) can be written as:
(b)#
Given values for \(v\), \(\theta\), \(\ddot{x}\), and \(\ddot{y}\), under what circumstances can you solve for \(a\) and \(\omega\) uniquely? Clearly state the mathematical condition(s) required for a unique solution to exist, and briefly explain the reason behind these conditions.
(c)#
Let us define the flat outputs for the system as \(\begin{bmatrix} x & y \end{bmatrix}^T\). Recall that the dynamics of the extended unicycle model allow us to interpret the second derivatives \(\ddot{x}\) and \(\ddot{y}\) as virtual control inputs: specifically, \(\begin{bmatrix} u_1 & u_2 \end{bmatrix}^T = \begin{bmatrix} \ddot{x} & \ddot{y} \end{bmatrix}^T\). By selecting appropriate values for the flat outputs and their second derivatives, it becomes possible to algebraically compute the corresponding physical control inputs, \(a\) and \(\omega\).
Suppose we wish to design a trajectory for the robot’s position in the plane, that is, a desired path \(\begin{bmatrix} x(t) & y(t) \end{bmatrix}^T\) specified as a function of time. One convenient approach is to parameterize this trajectory using basis functions, such as polynomials:
where \(\psi_i(t)\) for \(i=0,\dots, n\) are chosen basis functions (e.g., polynomials), and \(x_i\), \(y_i\) are scalar coefficients to be determined. The goal is to select these coefficients such that the resulting \(x(t)\) and \(y(t)\) satisfy desired initial/final conditions and possibly other requirements (e.g., velocity, boundary constraints).
(i)#
Consider the polynomial basis functions:
Formulate a system of linear equations in the coefficients \(x_i\) and \(y_i\), for \(i=0,\dots, 3\), so that the resulting trajectories \(x(t)\) and \(y(t)\) satisfy the following initial and terminal boundary conditions (with \(t_\text{f} = 15\)):
Initial conditions:
\[ x(0) = 0, \qquad y(0) = 0, \qquad v(0) = 0.5, \qquad \theta(0) = -\frac{\pi}{2} \]Final conditions:
\[ x(t_\text{f}) = 5, \qquad y(t_\text{f}) = 5, \qquad v(t_\text{f}) = 0.5, \qquad \theta(t_\text{f}) = -\frac{\pi}{2} \]
Provide the explicit linear equations relating the coefficients to these boundary conditions. Then, solve for the values of \(x_i\) and \(y_i\) that satisfy these constraints.
(ii)#
Explain why it is not possible to specify \(v(t_\text{f}) = 0\) in this formulation. What issues would arise if you tried to enforce this condition? Provide a mathematical or geometric justification.
(iii)#
Given the polynomial coefficients you have obtained, derive explicit expressions for the heading angle \(\theta(t)\) and the speed \(v(t)\) as functions of the trajectory \([x(t), y(t)]\) and their time derivatives.
(iv)#
Generate plots of the resulting trajectory by displaying \(x(t)\) and \(y(t)\) in the plane, as well as time profiles of \(\theta(t)\) and \(v(t)\) for \(t \in [0, t_\text{f}]\). Confirm graphically and/or numerically that the trajectory meets the prescribed initial and final conditions for position, heading, and velocity. Additionally, plot the time histories of the control inputs \(a(t)\) and \(\omega(t)\) along the trajectory.
Note: You may find that in the case with velocity constraints, the solution obtained above could violate them. There are several ways to address this.
Increase the number of basis polynomials and solve a constrained trajectory optimization problem. This is akin to a pseudospectral trajectory optimization approach; we can provide a trivial objective function and simply find a feasible solution.
Increase \(t_\text{f}\), essentially “stretching out” the trajectory, until the constraints are satisfied.
Re-scale velocities the problematic portions of the trajectory while keeping the geometric properties the same.
Take a look at the Stanford AA 274 homework if you are curious to learn more about the third option.
Sequential Decision Making#
1. Dynamic programming: Shortest path in a graph#
(Adapted from Stanford AA 203 homework)
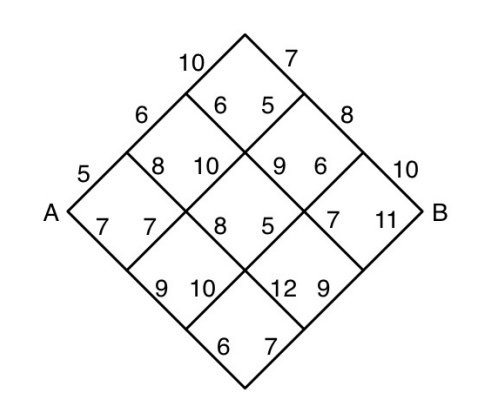
Consider the shortest path problem in figure above where it is only possible to travel to the right and the numbers represent the travel times for each segment. The control input is the decision to go “up” or “down” at each node. Given that state transitions are deterministic in a low-dimensional state space, we will use dynamic programming to develop a closed-loop policy for each node in the grid.
(a)#
Use dynamic programming (DP) to find the shortest path from A to B.
(b)#
Consider a generalized version of the shortest path problem in Figure 1 where the grid has \(n\) segments on each side. Find the number of computations required by an exhaustive search algorithm (i.e., the number of routes that such an algorithm would need to evaluate) and the number of computations required by a DP algorithm (i.e., the number of DP evaluations). For example, for \(n = 3\), an exhaustive search algorithm requires 20 computations, while the DP algorithm requires only 15.
(c)#
Now consider an extended version of the problem where, instead of only moving one edge-length at a time, you may move in a given direction (either up-right or down-right) for 1, 2, or 3 consecutive edge-lengths in a single action. The cost structure is as follows:
A move covering 1 edge-length: sum of the edge’s cost minus 1.
A move covering 2 edge-lengths: sum of the two edges’ costs minus 2.
A move covering 3 edge-lengths: sum of the three edges’ costs minus 3.
For instance, starting from node A:
Moving up-right for 1 edge-length has a cost of \(5-1\),
Moving up-right for 2 edge-length, the cost is \(5 + 6 - 2\),
Moving up-right for 3 edge-length, the cost is \(5 + 6 + 10 - 3\).
Using this cost and action setup, employ dynamic programming to compute the optimal (minimum-cost) path from node A to node B.